
Traceye SubQuery is excited to offer cost-effective and reliable data indexing for newly-launched Layer2 rollups & appchains. You might know that indexing a new chain is often costlier as service provides do not offer shared indexing service for them. That’s because managing a full-fledged server and other critical infra setup is a complex and resource-intensive process. However, providers will struggle to get enough users for new networks to cover their allocated ROI.
Hence, the next option for indexing new chains is to dedicated indexer node, for ex- a Graph Node, which is ofcourse costlier compared to shared indexing option. To bring a solution, Traceye has come up with a unique ‘Bring Your Own RPC’ offering to reduce the indexing cost, making it almost equal to that of shared indexing service. Let’s dive in and learn more about how Traceye SubQuery is offering indexing support for newly-launched Layer2 rollups and appchains.
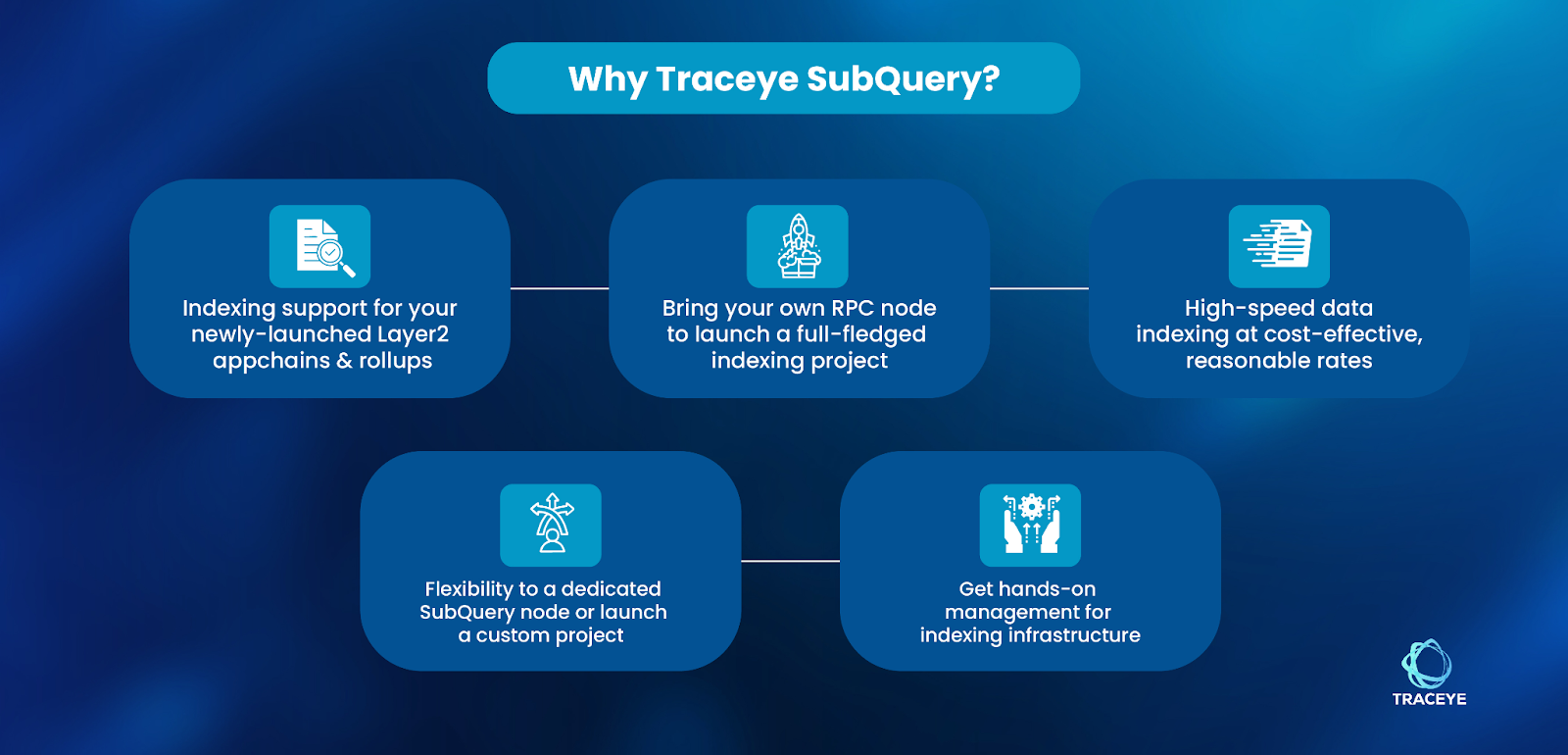
What makes SubQuery a great fit for Rollups and Appchains?
SubQuery is rapidly becoming a preferred option for Web3 projects to index blockchain data. Network’s unique offerings like scalable RPCs, open-source AI models, and innovative data nodes have made it a indexing hub of 240+ live projects, 108+ supported networks, and 28B+ queries. On SubQuery Network, projects have the option to launch SubQuery Data node or use the multi-chain indexing feature. With a data node, you get a dedicated node that is optimized for high throughput, unlimited queries, and top-notch security. Speaking about the muti-chain feature, a single endpoint will index data from diverse networks. For example, you can fetch transactional data from Polkadot Parachains while also tracking IBC messages on Cosmos. To achieve this, SubGraph uses ‘Dictionary’, which works through GraphQL schema and mapping files to avoid storing transactional data in the database. Both the indexing options has their own relevance based on projects and specific use cases. However, these services create challenges when it comes to indexing new Layer2 chains. Let’s talk about them.
The Indexing challenge in Newly-launched Rollups and Appchains
Indexing data from popular Layer2s like Arbitrum, Optimism, Polygon, or ZKsync Era is simple and cost-effective because these networks are available on almost all the indexing platforms. We already highlighted that shared indexing is enabled through indexing projects deployed on the dedicated node, hence a good amount of investment goes into setting up and maintaining infrastructure for the underlying dedicated node.
If it’s about high-traction networks, service providers can easily cover up the cost and make the desired ROI by having multiple customers. However, the same is difficult to achieve in the case of newly-launched Layer2 rollups and appchains because of their early-stage adoption and small community. Hence, the only option left for developers is to go for a dedicated node, which is again a costly option.
To provide a solution, Traceye is offering ‘Traceye SubQuery’ that brings a cost-efficient and reliable option for data indexing in new Layer2 rollups and appchains. Let’s learn more about this.
How Traceye SubQuery provides a solution?
Traceye SubQuery offers a high-quality, cost-efficient data indexing service for developers and rollups/appchain community. All the leading networks supported on SubQuery, plus the newly-launched Layer2 rollups and apppchains that are yet to get widespread adoption. For this, Traceye SubQuery offers the following two viable options:
1. Bring your own archive RPC & SubQuery dictionary
The ‘Bring your own RPC’ is designed to offer a cost-effective data indexing option for developers while ensuring a reliable performance. Under this setup, developers need to bring their own archive RPC and SubQuery dictionary to quickly launch an indexing project for new Layer2 rollups and appchains. And, the cost for this offering will be similar to that of deploying Subgraphs on shared infrastructure. Having existing archive RPCs and Dictionary reduces the infrastructure cost on the provider’s (Traceye) end, which allows it to offer affordable data indexing. That means it’s a win-win situation for both.
Note that RPCs and Dictionary are something you just need to provide once; their further management, optimization, and other critical operations will be handled on Traceye’s end. Therefore, you do not need to worry about performance & infra anymore.
2. Deploy a dedicated SubQuery node:
Like we discussed, developers can also launch a dedicated SubQuery data node for their preferred network, including newly-launched rollups and appchains. All the benefits of a node, like single-use, high-performance infra, dedicated throughput, and blazing fast queries, will come with the dedicated SubQuery node. However, the cost will be higher due to dedicated setup like management of dedicated servers, hardware components and fulfilling specific security requirements. Hence, this option is more suitable for indexing projects that are seeking to set up multiple indexers on their node’s infrastructure.
Besides the indexing challenge, one common problem for newly-laucnched Layer2 rollups and appchain is to build their community of developers and data consumers. Here’s how Traceye can assist them:
Build & empower your community with Traceye:
Traceye allows new public networks– be it Layer2 rollups or appchains, to integrate their network on Traceye platform and make it available for indexing, thus allowing them to empower their developer community with a affordable indexing service. To do this, Traceye will,
- Add your public network to Traceye’s indexing service.
- Allow you to offer services like hosted subgraph service, ultra-discounted DeFi community subgraphs, and dedicated SubQuery node option.
- Customize your indexing to offer a whitel-labeled indexing solution.
- Enable managed indexing services.
- Get access to the below value-added services.
Value-added services on Traceye SubQuery:
Traceye SubQuery does not focus only on offering low-cost data indexing, it goes further to bring you value-added services to streamline the indexing process:
- BI Analytics tool– Traceye SubQuery offers BI analytics tools as an off-ad service that projects can utilize to convert complex on-chain data into insightful information displayed with graphs, charts, tablets, etc. Plus, the tool gives you the flexibility to customize your data reports for a personalized data viewing.
- Real-time webhooks– Another critical add-on service on Traceye is Webhooks. This allow developers to retrieve real-time data in addition to their access to indexed database. Note that, real-time data is extremely important for new-age applications, be it gaming, AI, DePIN, DeFi, or even general-purpose apps.
- 24/7 Monitoring dashboard- To ensure the performance and uptime of your indexing project, Traceye SubQuery offers a default 24/7 monitoring dashboard to keep track of live performance, spot any issues, and resolve them immediately. Some of the critical monitoring parameters are CPU usage, memory, RAM utilization, cloud resources, and more.
- Index & ledger data pruning- With the data pruning option, indexing projects can retain data for upto specific block height and prune rest of the data automatically everytme a indexing request is made. This allows for seamless query optimization, thus improving query performance.
- Custom entities- DeFi trading platforms, web3 games, NFT marketplace, and similar applications can use Traceye’s custom entities to ensure hands-on access to off-chain data within their indexer node.
Ready to launch your SubQuery indexing project?
SubQuery’s Layer2-specific offering and a bunch of innovative features have already gathered attention of leading projects and it’s set to project tremendous growth going forward. Hence, the requirement for cost-effective indexing will rise. If you also look for reasonable indexing service, especially for newly-launched rollups and appchain— Traceye is your ideal indexing solution. Ofcourse, you’ll get all the features that we discussed in this article. Plus, Traceye is open to discuss any customization you need for use case-specific requirements. For more information about Traceye SubQuery, and its comprehensive indexing services, connect with us. Also, you can schedule a quick demo for a better demonstration.

Product Director & an intrapreneur with a focus on intersection of technology and business models. Having 10+ years of experience in consulting, software design & architecture, product and project management. Career track follows working on ERPs, Consumer & Enterprise products, stints in AI & Machine Learning and finally settling in decentralization & Blockchain space.